Accepted at AISTATS 2026
Speculative Decoding
Efficient LLM Inference
DIVERSED: Relaxed Speculative Decoding via Dynamic Ensemble Verification
A project page for our AISTATS 2026 paper on relaxing speculative decoding verification with a learned, context-dependent ensemble of draft and target distributions.
Purdue University · Amazon Inc. · University of Illinois Urbana-Champaign · University of Texas at El Paso
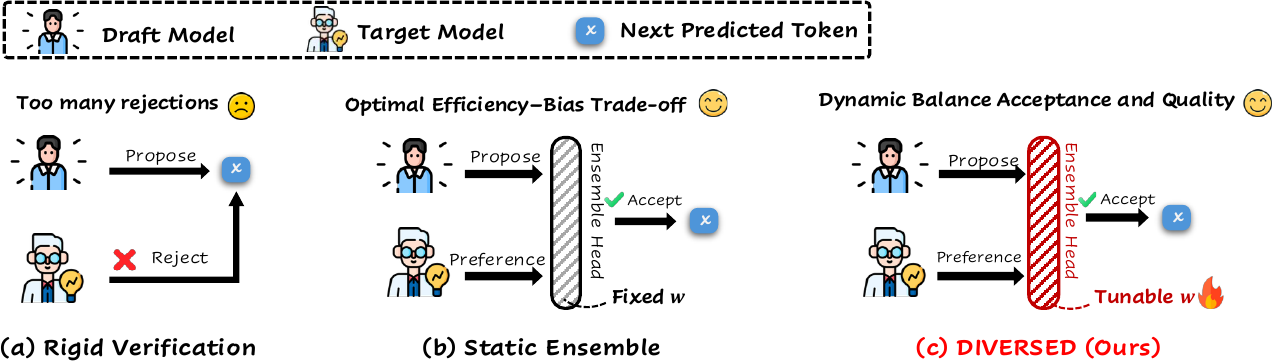
Teaser. Standard speculative decoding is often overly conservative: many useful draft tokens are rejected because verification must exactly match the target distribution.
DIVERSED replaces that rigid rule with a learned, dynamic verifier that accepts more safe tokens while preserving final quality.
TL;DR
Speculative decoding speeds up LLM generation by drafting multiple tokens and verifying them in parallel. In practice, the bottleneck is often not drafting - it is rigid verification. DIVERSED learns when to stay close to the target model and when it is safe to lean more on the draft model, improving acceptance and end-to-end efficiency.
Core idea
Dynamic ensemble verifier
Blend draft and target distributions with a context-dependent weight.
Theory
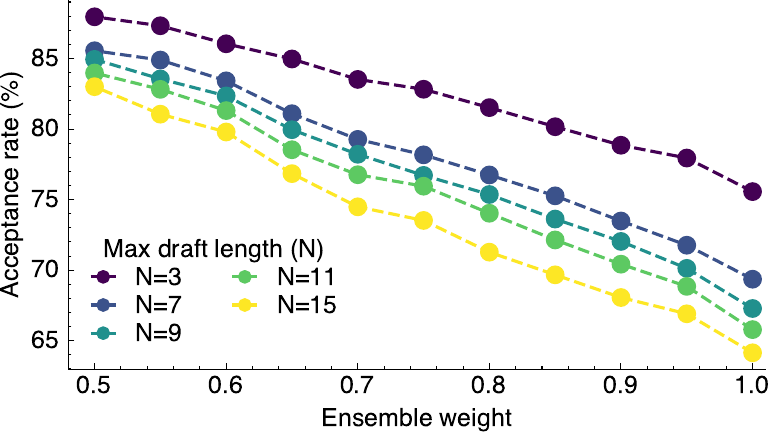
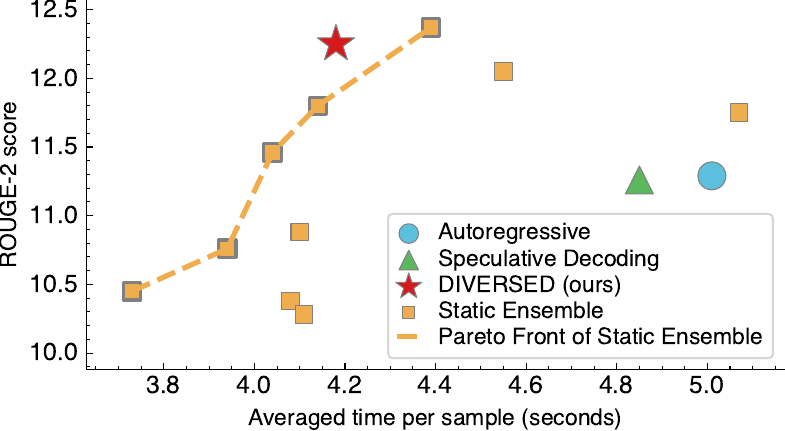
Static ensemble traces the Pareto front
A fixed-weight mixture characterizes the acceptance-quality trade-off.
Training
Sequence-level RL
The verifier is trained using task reward plus an acceptance regularizer.
Outcome
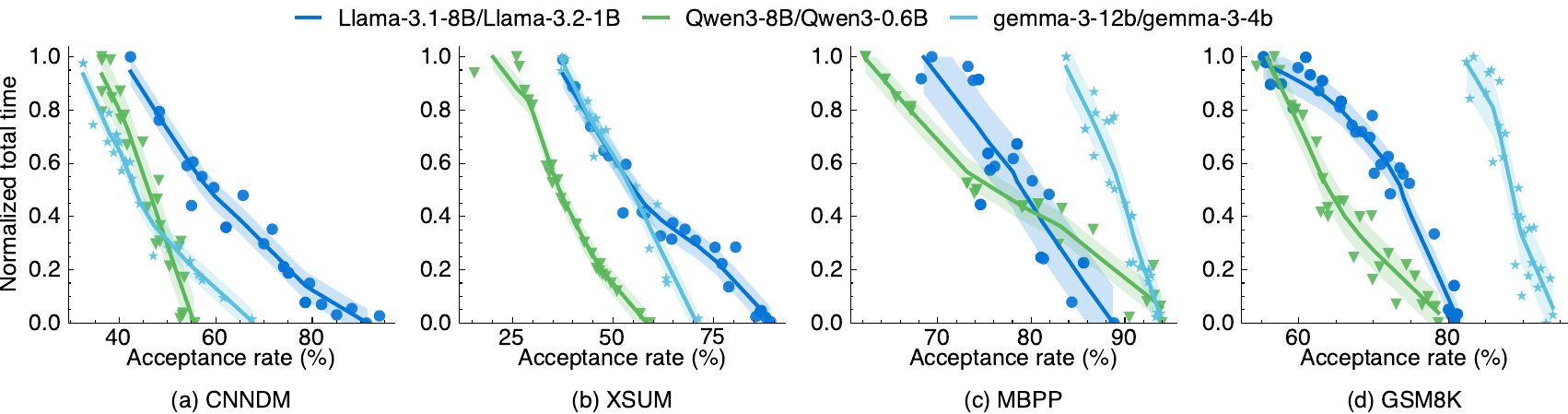
Higher acceptance at similar quality
Across summarization, reasoning, and code generation.